Profundizando en Tensorflow. Pt. 1
Plataforma de Aprendizaje Automático de Google
Por Oscar Chávez (@oschvr)
Tensorflow es una plataforma a código abierto de aprendizaje automático para todos.
Estrictamente es una libreria para computación numérice mediante gráficos de flujo de datos.
Los nodos en los gráficos representan operaciones matemáticas, mientras que los bordes de los gráficos representan las matrices de datos multidimensionales (tensores) comunicadas entre si.
Tensores
La unidad central de Tensorflow es el tensor. Un tensor consiste en un conjunt de valores primitivos modelados dentro de un arreglo de cualquier dimensión. El rango de un tensor es el número de dimensiones.
[1. ,2., 3.] # es rango 1; este vector tiene forma [3]
[[1., 2., 3.], [4., 5., 6.]] # es rango 2; este vector tiene forma [2, 3]
+++
Tutorial Introductorio
Primero que nada, para llevar a cabo este micro-tutorial, debemos tener instalado Tensorflow.
Los requisitos que debemos tener:
- Programar en Python
- Saber un poco de arreglos
- Idealmente saber algo de aprendizaje automatico, pero no necesariamente
En mi ambiente (macOS) está instalado:
- Tensorflow 1.2
- Python 3.6
Ambiente
Debesa activar el virtualenv y e invocar python:
$ source ~/tensorflow/bin/activate
(tensorflow) bash-3.2$ python
Python 3.6.1
-> ya estás en python
Importar tensorflow
import tensorflow as tf
Esto le da a Python, acceso a las clases, metodos y símbolos de Tensorflow
Grafo Comptuacional
¿Qué es un grafo?
El Core de Tensorflow consiste en dos seciones discretas:
- Construir el grafo computacional
- Correr el grafo computacional
Un grafo computacional consiste en una serie de operaciones de Tensorflow arregladas a manera de un grafo de nodos.
Nodos
Crearemos un grafo computacional simple. Cada nodo en el grafo recibe cero o más tensores como entrada y produce un tensor como salida. Un tipo de nodo es una constante en Tensorflow.
node1 = tf.constant(3.0, dtype=tf.float32)
node2 = tf.constant(4.0) # tf.float32 implicito
print(node1, node2)
Esto imprime
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32)
Para realmente evaluar los nodos cuyos valores definimos 3.0 4.0, debemos Correr el grafo computacional dentro de una sesion. Una sesion encapsula el control y el estado del runtime de TF.
sess = tf.Session()
print(sess.run([node1, node2]))
Esto imprime los valores de nuestros nodos
[3.0, 4.0]
Si queremos realizar computaciones más complejas, podemos combinar nodos Tensores con operaciones (las operaciones también son nodos)
node3 = tf.add(node1, node2) # tf.add
print(sess.run(node3))
Esto imprime:
7.0
Tensorflow tiene una herramienta que nos permite visualizar nuestros grafos computacionales, llamada TensorBoard. Así se visualiza nuestro grafo en Tensorboard:

Realmente nada ninteresante por que siempre producirá un resultado constante.
Placeholders
Sin embargo, un grafo puede ser parametrizado, es decir, puede aceptar parámetros o entradas externas, conocidas como placeholder. Un placeholder es una promesa para proveer un valor después.
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
adder_node = a + b # shortcut de tf.add(a, b)
Definimos una funcion y luego un valor sobre los parámetros print(sess.run(adder_node, {a: 3, b: 4.5})) print(sess.run(adder_node, {a: [1, 3], b:[2, 4]}))
Resultado:
7.5
[3. 7.]
Así se ve en TensorBoard nuestro grafo
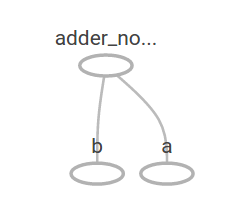
Podemos hacer el grafo computacional más complejo. Por ejemplo
add_and_triple = adder_node * 3.
print(sess.run(add_and_triple, {a: 3, b:4,5}))
Resultado:
22.5
y así en TB:
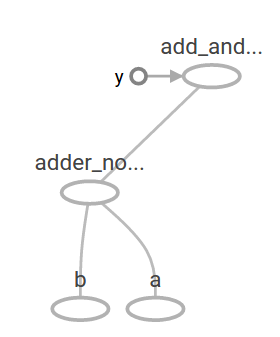
Variables
En el aprendizaje automático, quermos que un modelo pueda tomar entradas arbitraias. Para poder hacerlo entrenable, debemos poder modificar el grafo para obtener diferentes resultados con la misma información de entrada. Las variables nos permiten agregar elementos entrebables a un grafo.
W = tf.Variable([.3], dtype = tf.float32)
b = tf.Variable([-.3], dtype = tf.float32)
x = tf.placeholder(tf.float32)
linear_model = W * x + b
Las constantes se inicializan cuando llamamos tf.constant, y su valor no cambia. Las variables, en cambio no se inicializan cuando llamamos tf.Variable. Para inicializar todas las variables en un programa de TensorFlow, debemos hacer lo siguiente:
init = tf.global_variables_initializer()
sess.run(init)
Hasta que no llamemos sess.run(init) las variables no se van a inicializar.
x es un placeholder, por lo que podemos evaluar linear_model para varios valores de x simultaneamente:
print(sess.run(linear_model, {x: [1, 2, 3, 4]}))
que produce:
[ 0. 0.30000001 0.60000002 0.90000004]
Creamos un modelo, pero no sabemos que tan bueno es. Para evaluar un modelo con datos de entrenamiento (training data), debemos crear un placeholder ypara proveer estos valores, así como una funcion de pérdida
Funcion de Pérdida (Loss Function)
Una función de pérdida o loss function mide que tan lejos está nuestro modelo de los datos provistos o de entrenamiento. Utilizaremos un modelo de pérdida estándar para regresión lineal, que suma los cuadrados de los deltas entre el modelo actual y los datos provistos.
linear_model - ycrea un vector donde cada elemento corresponde al error del delta del ejemplo.- Llamamos
tf.squarepara conseguir la raíz cuadrada de ese error. - Y luego sumamos todos las raices de los errores para crear un scalar que abrstae el error de todos los ejemplos usando
tf.reduce_sumy = tf.placeholder(tf.float32) squared_deltas = tf.square(linear_model - y) loss = tf.reduce_sum(squared_deltas) print(sess.run(loss, {x: [1,2,3,4], y:[0,-1,-2,-3]}))
Produciendo el valor de pérdida:
23.66
Podríamos mejorar nuestra pérdida al reasignar manualmente los valores de W y b a -1 y 1. Sin embargo podemos utilizar operaciones como tf.assignpara cambiar los valores. Por ejemplo, W=1y b=1son nuestros valores óptimos.
fixW = tf.assign(W, [-1.])
fixb = tf.assign(b, [1.])
sess.run([fixW, fixb])
print(sess.run(loss, {x:[1,2,3,4], y:[0,-1,-2,-3]}))
Teniendo una pérdida de 0.0 como resultado.
Adivinamos los valores “perfectos” de W y b, pero el punto del aprendizaje automático es encontrar los parámetros para el modelo de manera automática.
Pronto Parte 2